An introduction to Signal Engineering

The following post is the kind of post, that I was looking for, when I started to research the topic about 12 months ago.
I read about Signal engineering at the usual place - LinkedIn - quite a while ago. And it triggered the marketing snake oil radar quite hard. Truth to be told, the radar is set to very sensitive for these kind of topics after being in this space for quite a while.
But the kind of posts had all the good ingredients of a classic martech scam: simple solution for a complex problem, big promises of better ad performance and a you just need to install this or do this to get it implemented.
This moved signal engineering on my backlist of topics like, conversion modeling or the little brother server-side tag manager. I know that sGTM can have it benefits, same as conversion modeling has. But these are topics that are constantly oversold without clear values for marketing teams. Conversion modeling with these bold claims of increasing your Facebook ROAS (omg, we can now spent more money on Meta without having any clue if it really makes sense) and server-side tag manager as a quasi default for measurement (your data quality is screwed up when you don’t do it). Everything I read about signal engineering had the same tone.
Then I saw it in combination with server-side tag manager. And again, nothing really groundbreaking. Yeah, now you enrich the data that you sent back to ad platforms with data from your backends or CRM. Well, we did this already via conversion APIs on top of the data warehouse. So nothing groundbreaking then.
But when in doubt, a good podcast can help to make things clearer:
Season 6, Episode 6: What is signal engineering? with Itai Kafri
In this podcast episode of Erik Seufert’s Mobile Dev Memo podcast he sits down Itai Kafri to discuss signal engineering. And this episode finally made it clear to me why are some serious people are serious about it. Itai does a great job to explain why signal engineering becomes so important today and what are the challenges of it. This gave me the right foundations to first understand why it is relevant today and what makes it so complicated, that it goes beyond just another server-side tag management setup or by using conversion APIs.
In the following I am trying to explain the context, why it does matter today, what are the ingredients of it and how to implement it. Along the way I am trying to bust some myths (like it is simply a data science problem). My hope is that that by the end you have a solid understanding of what signal engineering is, when it becomes relevant in your setup and what you need to have in place for it.
Upcoming workshop
Go deeper on signal engineering
Join the live workshop where we turn the concepts from this post into a practical signal architecture for paid marketing teams.
Reserve your seatSignal engineering in a nutshell
Technically you are doing signal engineering already right now when you run campaigns on any digital ad platform. I assume that you all use some kind of conversion tracking that is sending a conversion back to Google Ads, Meta or any other platform. This is a conversion signal. We are using it since the dawn of digital paid advertising. So where does the engineering come in. It comes in when we decide when and what we are sending back. In the classic conversion tag case we assumed that is natural: we send a conversion when something meaningful has happened, like a purchase or a registration and the value is the revenue we converted or a blended static value for a conversion. In this scenario we assumed the time and value are obvious ad therefore fixed.
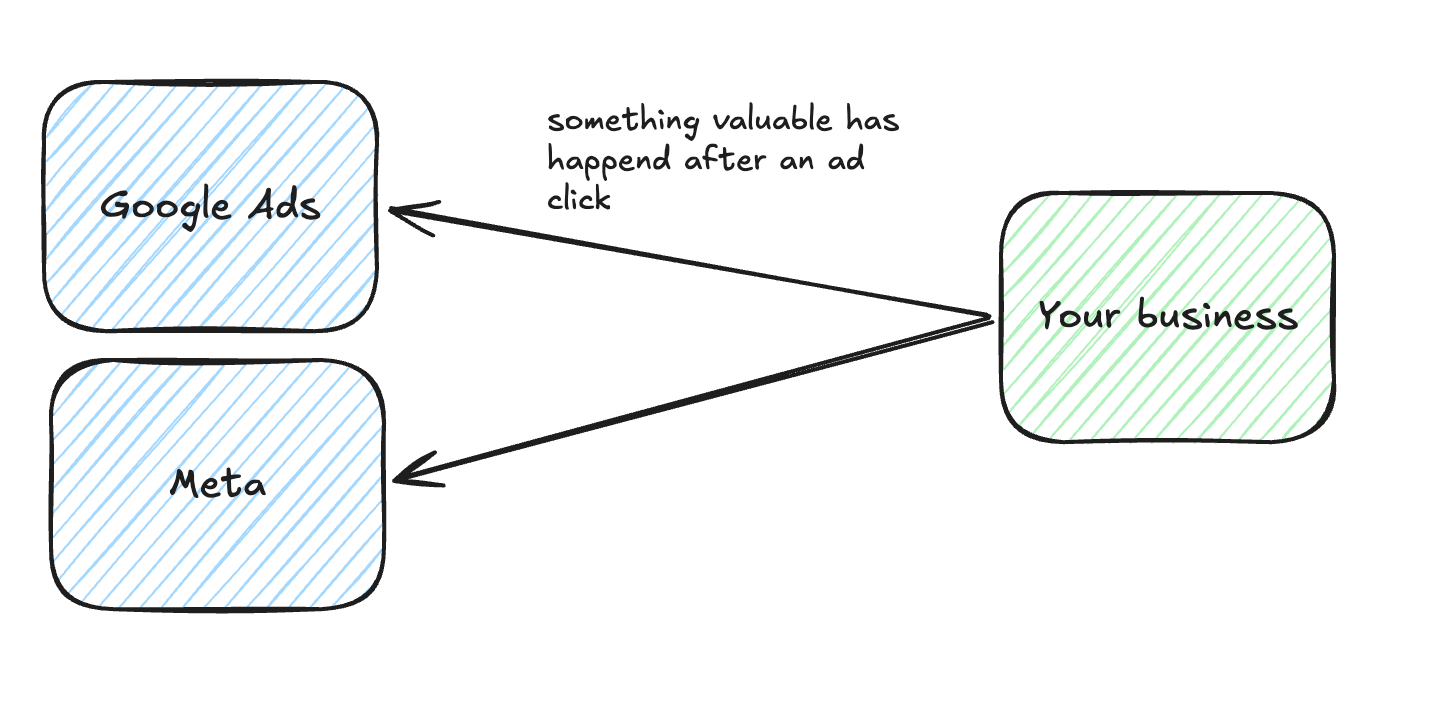
But signal engineering is exactly about treating this dynamically. When do we send a signal back and what value should we provide? And how often do we send this signal?
What has changed that this became important?
Why aren’t the classic approaches of sending a conversion when it happens not working anymore (when they have been the default model for quite a long time and are still for most companies).
Two main reasons: business models have evolved and campaign setups and optimization as well.
About business models
I still have the feeling that a lot of perceived knowledge about marketing measurement derives from a very niche setup: you have a simple arbitrage use case. Meaning the product you sell, is commodity enough that people can decide in a session to buy it and you basically live of the immediate achieved margin. Like usb cables.
These models exist and there was a time where they had a dominant position. But this was only true for a short period of time. Today in over-saturated marketing channels you find most business models optimizing for future revenue (aka the famous customer lifetime value), which can be either supported by subscription products or advanced retention marketing. The same dynamic shows up even more sharply in B2B, where sales cycles routinely stretch across months and the conversions that actually matter, signed contracts and renewals, often happen well outside any platform’s lookback window. We come back to this in the timing section. Additionally if you want to grow significantly enough, just capturing the buying-intent users via search engine marketing is not enough, you need to tap into marketing setups that capture awareness much more than immediate buying.
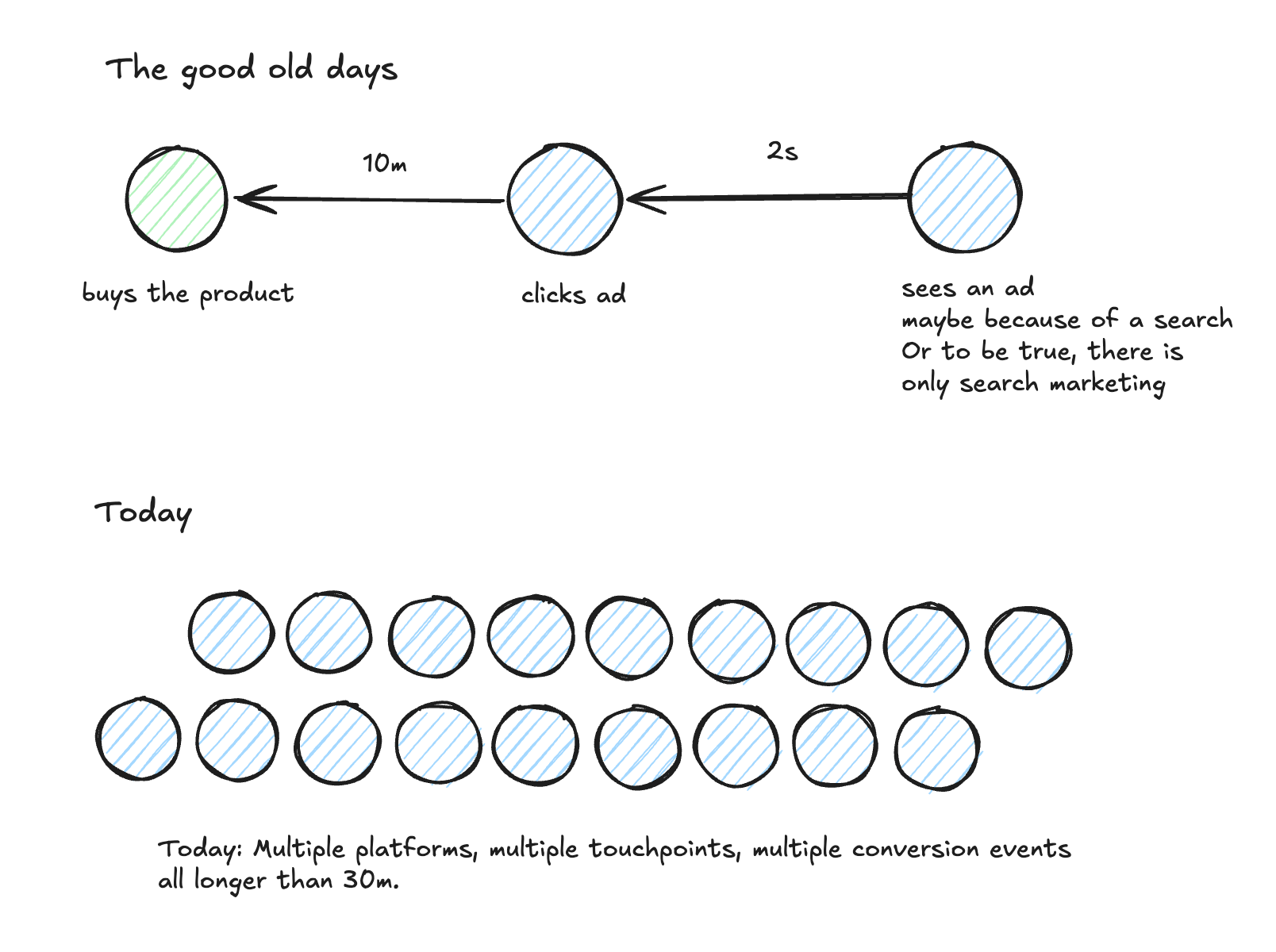
Then you can see a significant increase in B2B marketing efforts using ad platforms. Triggering and supporting journeys that take a long time to finally convert. A science of its own.
About the ad setups
Then the ad space has changed significantly. On the one side due to the shifts in the business models (and over-saturation) of existing setups, but also due to regulations. With GDPR and ATT the baseline of measurable signals has been reduced up to 50-60% of the former signal volume. Consent rates in Europe sit around 60-70% on average, which means roughly a third of your traffic is invisible to client-side tracking by default. Modeled conversions and consent mode setups can recover part of this, but only within the consent boundaries you have already established.
So the platforms adapted. At the forefront Meta that was hit the hardest by Apple’s introduction of ATT (Meta’s setup until then due to unique device identifiers was superior to find audiences quite similar to the ones already buying). These high quality signals disappeared almost over night when iOS 14.5 was rolled out.
Meta’s answer to this in laymen terms was to shift from a very deterministic approach (where one click, one conversion could be attributed to one meta profile with it’s rich property set) to probabilistic approach where the performance analysis and audience handling was moving behind the scenes into the black box (it was a black box before but now more). Google also saw diminishing happiness in setups with overcrowded keywords (here is your click for 15 USD) and the amount of overcrowded keywords growing.
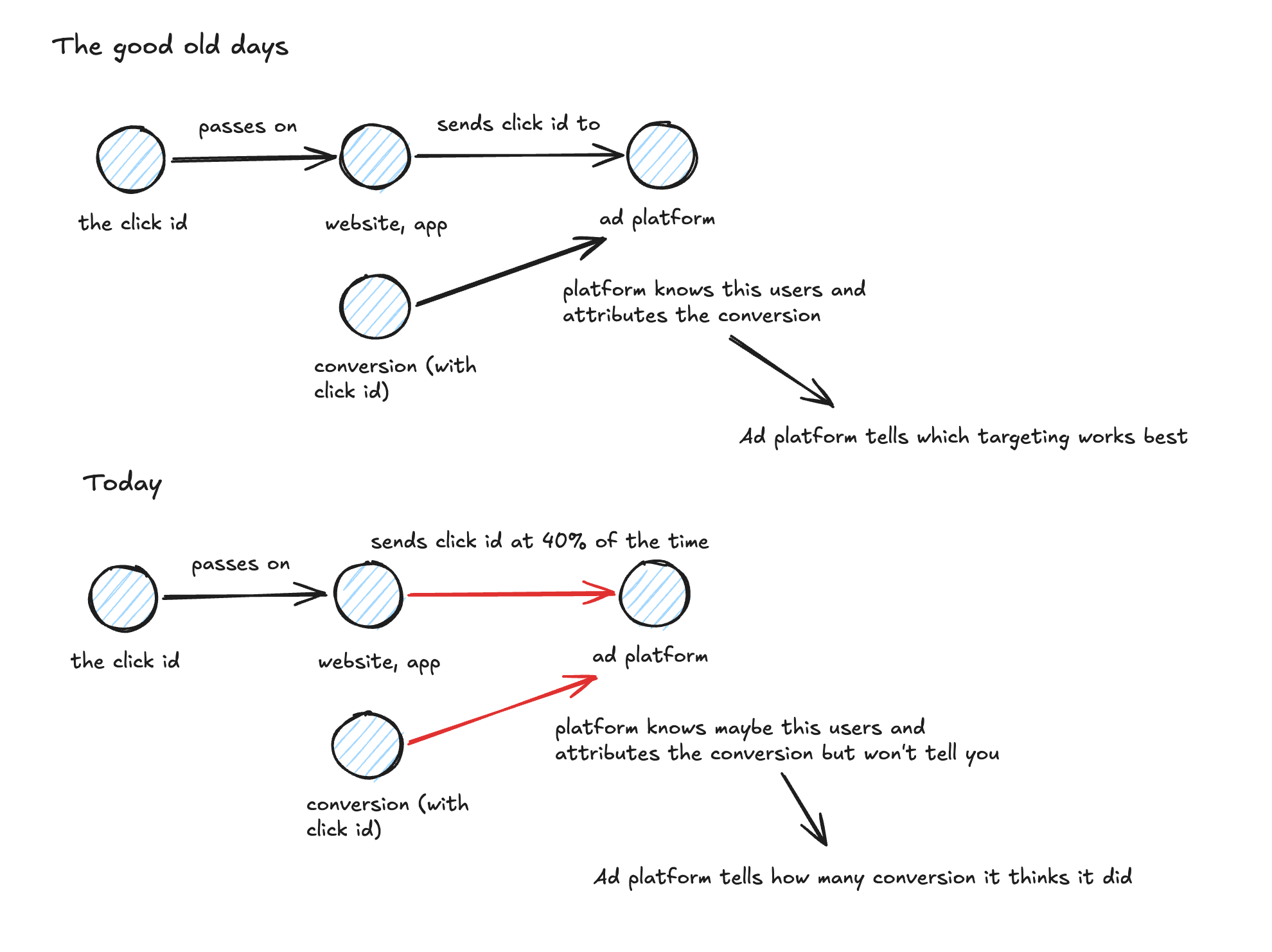
The result for both platforms was to invest into campaign types that move the optimization inwards to the platform, by reducing the targeting and optimization options for marketing teams. In gist, the new strategy was and is, we have this huge bucket of potential buyers, we don’t let you slice and dice it anymore like you could before because it became to hard to find the right configuration. Why don’t you let us do that for you, because we have much better data (that we will never share with you) and advanced probability models that only we could train on our datasets.
This means for marketing teams, tell us about your conversions and we find more of these potential buyers and send them your way. But please make sure that you send them in the first 24h because later the impact of our ads is decreasing dramatically. So your conversion for a purchase sent via API 5-14 days after an ad click (a totally reasonable journey time) becomes an extremely weak signal for us and we might struggle to find more of these potential buyers.
The timing conundrum
On the paper this all looks logically simple. Someone clicks and ad and comes to your website. If this person would immediately buy something, we would have straightforward case. This ad had a direct influence on the purchase. So the combination of the profile data, the ad messaging and targeting seems to big great. So the platform should try and test more of this combination.
But in our classic model this rarely happens. More likely, someone clicks an ad, checks the offers, doesn’t buy something, maybe she remembers later, maybe clicks another ad or comes back directly. So we are easily beyond the first 24h. And it can become worse. Let’s assume we offer a subscription because a one-time purchase would never generate positive returns on your ad spent. So now we technically we would send a conversion maybe after three subscription renewals if we want to be on the safe side. But during all this time, this person was exposed to so many different ads, that we can’t tell for sure the impact of the first one. And that’s why the ad platform do the same.
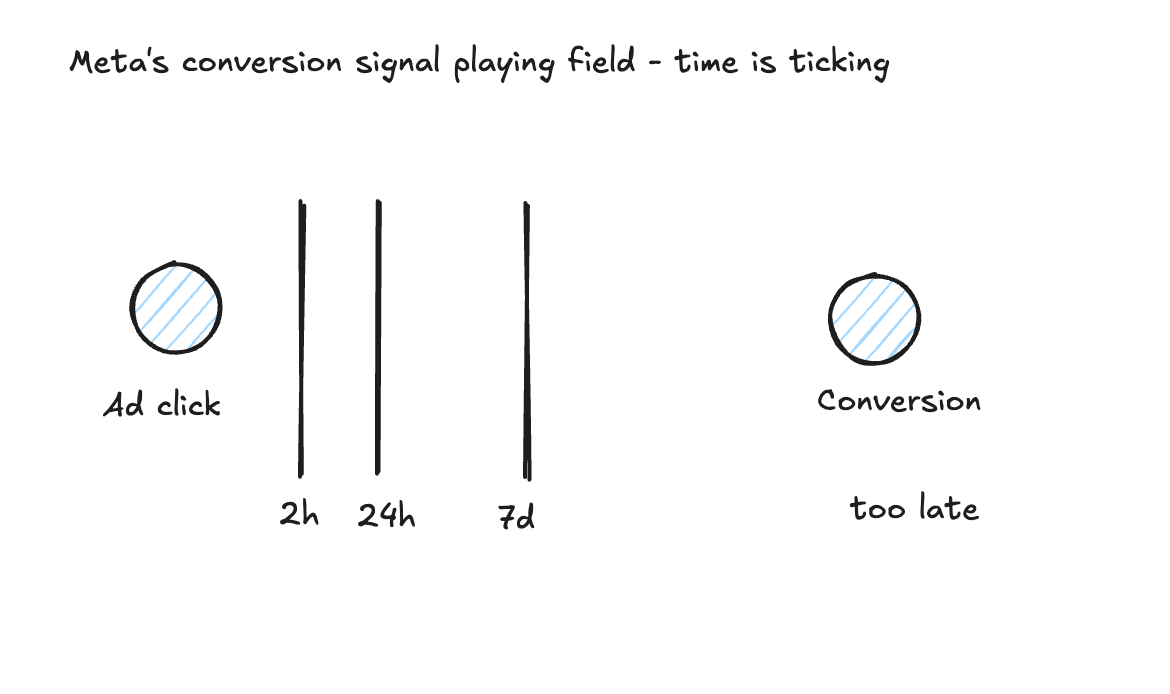
The platforms don’t all behave the same way here. Meta is the strict end of the spectrum. Their official Conversions API documentation classifies data freshness into just two buckets, real-time and hourly, and Meta’s Business Help Center on Conversions API best practices notes that events sent more than two hours after they happen cause noticeable performance decline, while events delayed beyond 24 hours start breaking attribution and ad delivery outright (Meta has a max click-attribution window of 7 days). Google is more forgiving. Performance Max and Smart Bidding are designed to tolerate conversion lag, accept offline conversion imports within a 90-day window, and backdate them to the click date. So on Meta you have hours, on Google you have weeks. Both are still windows you have to actively manage.
But Google’s tolerance comes with its own catch, and this is where most people stop reading too early. Yes, you can send a conversion to Google 60 days after the click. But what you’ve also done is tied your campaign feedback loop to the same 60 days. You change a creative, an audience, a value rule, and you have to wait weeks before the algorithm has enough late-arriving data to evaluate the change. Meanwhile your spend continues, your competitors don’t pause, and the market keeps moving.
There is a second problem. Late conversions are by definition deep-funnel events, which means they are scarce. If your closed-won volume sits below the platform’s learning thresholds, you cannot actually optimize on them, you have to fall back to a proxy event earlier in the journey. So the 90-day window is theoretical for a lot of B2B setups.
And there is a third problem, and this one is uncomfortable. A conversion that closes 60 days after the ad click was rarely caused by the ad alone. Sales calls, product trials, customer success conversations, internal champions, comparison shopping, all of them shaped the outcome. When you send that revenue back to Google as if the click was the reason, you are giving the algorithm a signal that carries credit it did not fully earn. The platform learns a partly wrong lesson. The counter-argument here is that a noisy revenue signal is still better than a clean lead signal, because leads do not pay you, and that is fair. But you should be honest with yourself that you are no longer optimizing on cause, you are optimizing on correlation that is increasingly contaminated the further down the funnel you go.
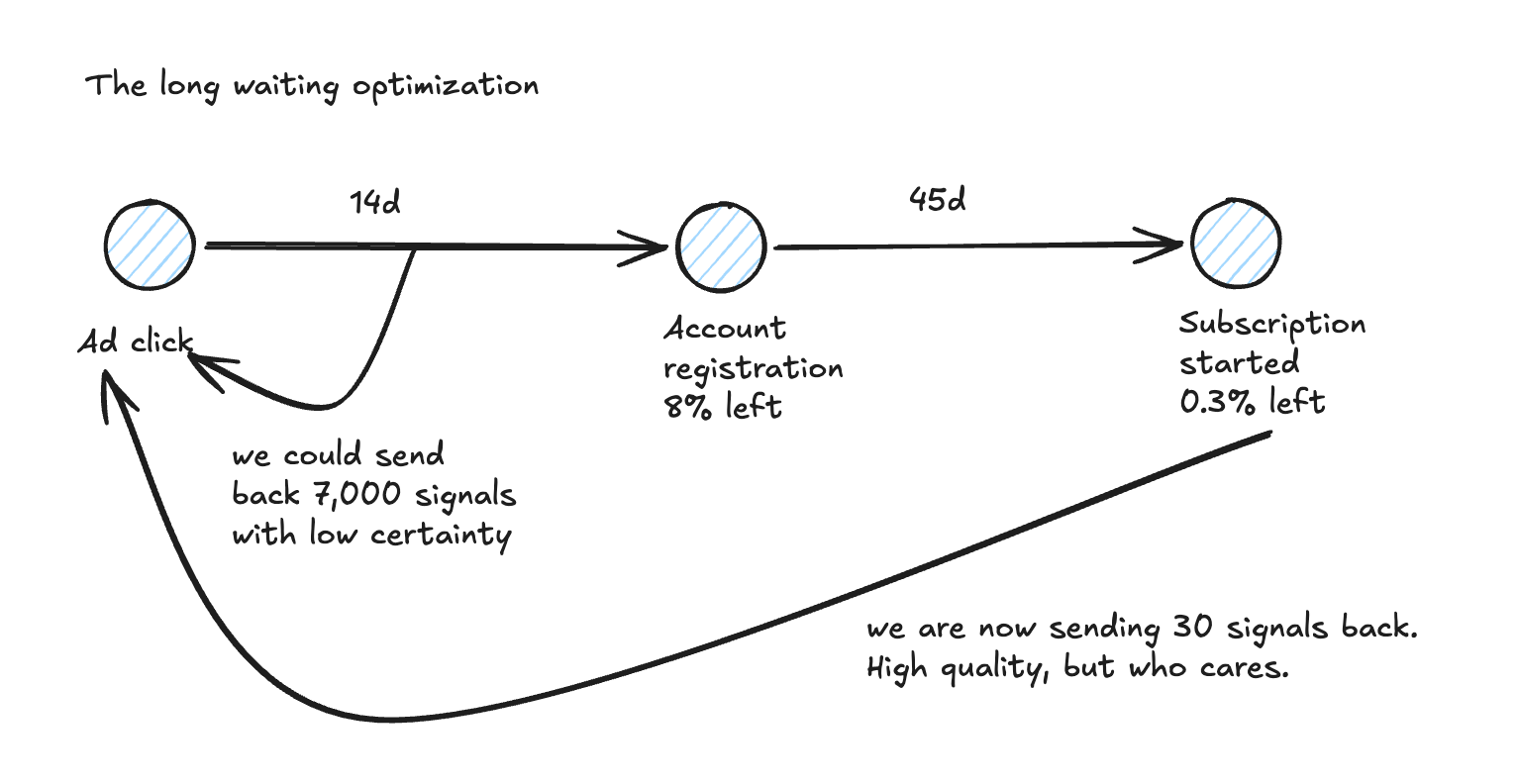
And you as a business now have to change your setup of late conversion signals to early conversion signals (without know about a conversion yet).
So we are also entering the space of probability like the ad platforms. Instead of waiting for a final conversion we are trying to make a prediction about future revenue. And we are not in a comfortable position since we just have 24h to do so. Quite small evidence isn’t it.
A case for the data science team?
When you are aware of this situation a natural step would be to sit down with the data team (assuming you have one) and talk to the data scientists especially. “Can’t we create a model by analysing post purchases, their behaviors, their zero party data, timings before the purchase?” And this model could then produce a set of specific behavior that can point to a higher probability when watched earlier. Things like visited 5 product detail pages, bookmarked a product, checked the delivery costs and terms, contacted us, shared the product. Maybe these signals are even so obvious that we can skip the data science part and just determine these behaviors by human sense and send earlier signals.
Problem solved? Well, you solved a part of the equation: sending a signal into a window of 24h. But now the next question let you stay awake, is this actually the right signal, or are we wasting clicks and ad-budget because the signals are good enough. So you need to solve signal timing and signal quality. Damn. And let me tell you there is a third thing you might not be aware of (I will tell you about it later).
Determining signal quality
Let’s quickly look back at our old signals. We sending a conversion when someone buys something. One part is great - purchase probability is between 80-100% (if people can return - so it is minus the avg. return rate). The value, at least the revenue of the initial purchase, or maybe a CLV on top. Obviously the best data quality would be present when we would determine everything after a year.
But this gives us already a hint what we need to look for. The future results. Our early signal is a proxy, so we need to compare the proxy with the future reality to see how well we did predicted it.
Can we do this with our existing measurement setup? Most likely not. Current measurement setups are focused on simple marketing touchpoint (aka the session), conversion measurement and maybe some micro conversion events. But signal performance measurement adds another layer to it.
What you need to add is an event stream for the signals that you are sending to the platforms, packed with useful meta-data and of course with all identifiers you can get at that moment.
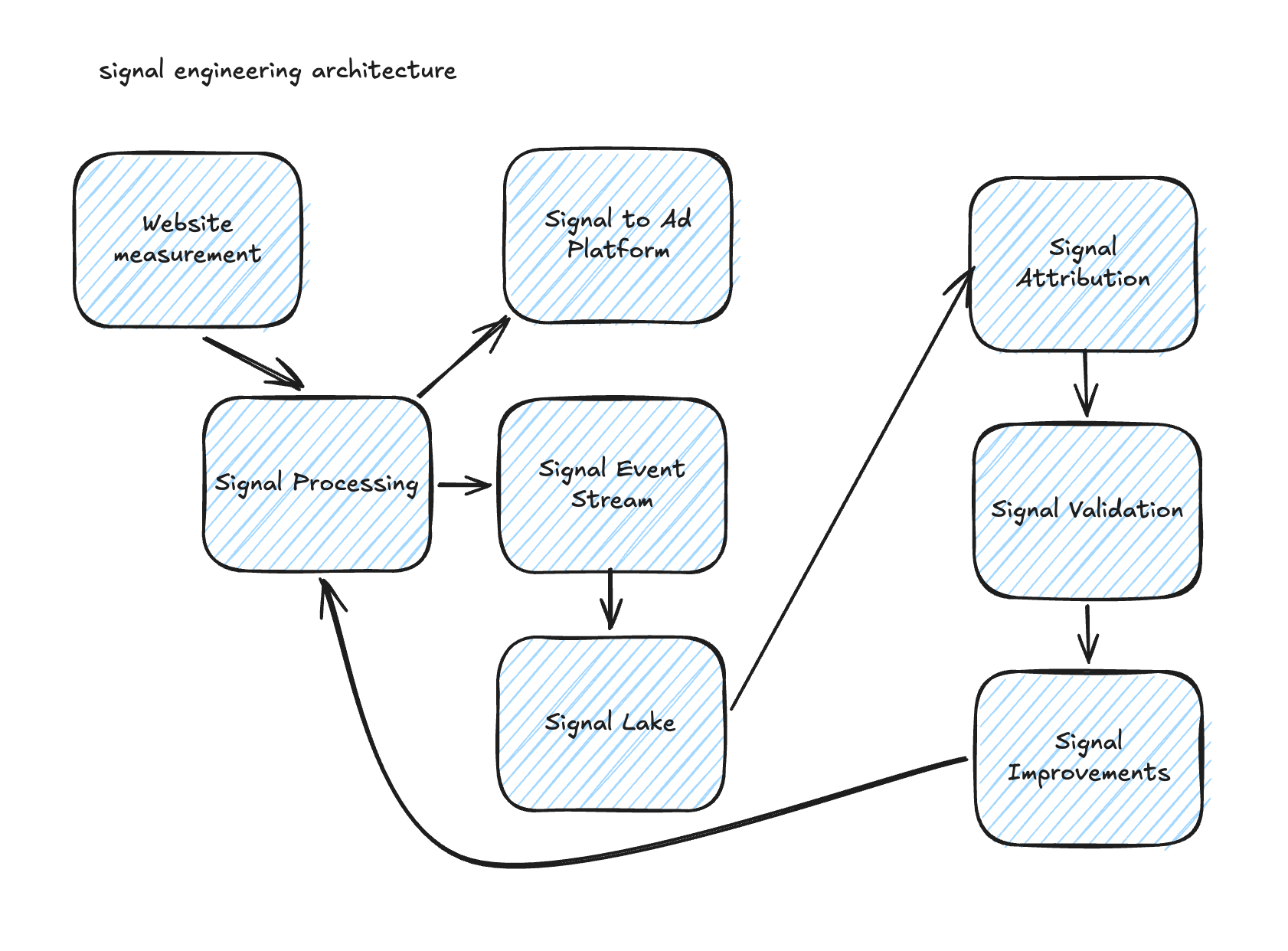
This is the foundation to later stitch these to your attribution data model and analyze how your predictions have turned out. You might need a proxy model in between when your final conversion take a longer time.
The core idea here is to create a constant feedback loop: testing signals, watching the qualification of these users to a final conversion, analyze signal quality, finetune, rinse and repeat.
This infrastructure is a core asset and not a nice to have part of the setup. And as you might have already read between the lines, you will most likely need a data warehouse for this.
One last thing on quality before we move on. So far I’ve been describing signals as if they are binary: this happened or it didn’t. They aren’t, and treating them that way leaves performance on the table. The value you attach to a signal is its own dimension. Sending “a purchase happened” is a fundamentally different message to the platform than sending “a purchase happened, predicted lifetime value 480 EUR.” The first lets the platform optimize for volume. The second lets it optimize for value, which is what unlocks tROAS on Google and value-based optimization on Meta.
I’ll be honest that validating values is harder than validating events. With a binary signal you can ask “did this user actually convert later” and get a clean answer. With values you have to compare a predicted number to an actual number, account for noise, drift, and the fact that your ground truth value is itself a model. That’s a longer topic for a follow-up. For now, just know that value is part of what you send, and it is where both the largest performance lifts and the largest blow-ups come from.
What you signal is what you get
Now we get to my favorite part. Remember the third thing? Solving timing tells the platforms when to listen. Solving quality tells them what to count. But there is a third dimension that only emerges once those two are running, and it is the one I find most people miss.
So far we believe this is a straightforward loop. We match signals with our predictions, once over the threshold we sent and log them, we monitor them, validate and refine them. Sounds pretty straightforward and linear.
Well, with our signals we introduce another gravitation and it can become a significant one in our setup.
Based on our criteria we are choosing and therefore the signals we are sending back, we signal our preferences of ideal users we want to get. We did this with our limited knowledge of potential customers and based on our validation of this specific group of people and their likelihood of revenue. But there might be so many other groups of people that would love to buy but our signals are not catching.
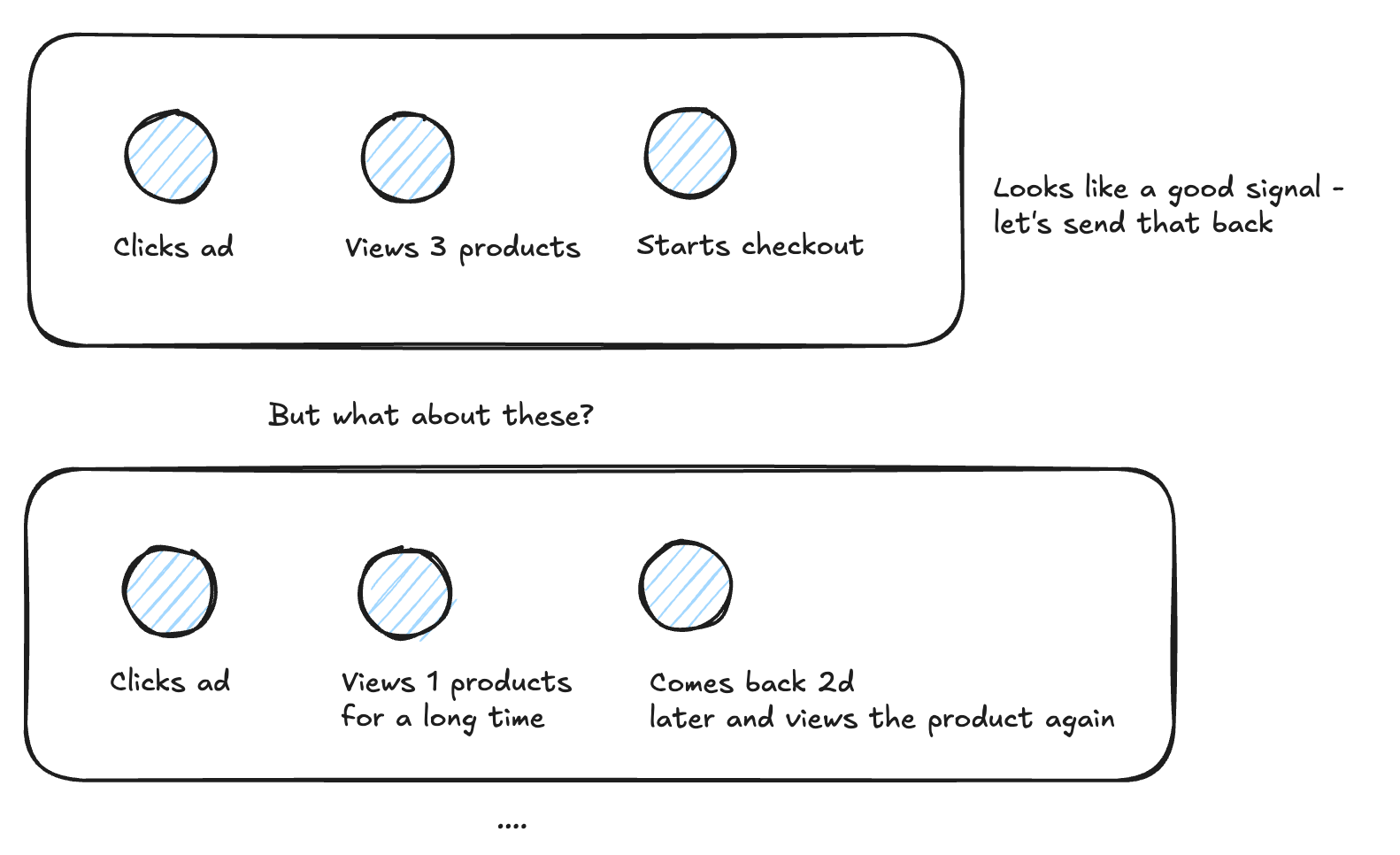
Whatever we signal back to the ad platforms we get more back.
So you need to make sure to have a setup that supports different pools of signals to constantly test and refine across different criteria. And you need to monitor if an audience is becoming oversaturated. The depths of this is a topic for a future post.
So, should we do this now?
The entry question is the same as for custom attribution, how much are you spending for paid ads. It’s always hard to put a number since it depends to some degree, but the question behind the question is conversion volume. The platforms need roughly 50 conversions per week per ad set on Meta to exit the learning phase, and 30 to 50 conversions per month at the account level for Google’s value-based bidding to stabilize. In our experience that translates to at least 100k USD per month in paid digital spend for most B2C setups, often more for B2B with smaller funnels.
Then you need ownership. Someone in your org needs to own this pipeline. And that is tricky one since it crossed marketing and data and there is no logical pick. If you have a marketing ops person or team, this could be a good fit. If not, I would most likely give it into the hand of the most technical, analytical marketing person. But this is a classic data + marketing teamwork setup and I know that this is a struggle in a lot of organizations. But maybe this is a good project to do something together (and trust this is more effective and fun than doing CDP projects together).
Wrapping up
I hope this introduction was helpful to understand the different levels and challenges but also the benefits that signal engineering can get you.
The main things for me for you to take away are:
- Signals are dynamic. It is not a one time, static value, micro conversion enriched with CRM data thing. Like almost everything. Attribution models are also never static
- What you signal you will get back, so you actively shape your audience, which is good and dangerous at the same time
- You need a solid architecture with tracking, monitoring, validation in place, since this becomes your paid traffic backbone. Therefore you need ownership for it.
Upcoming workshop
Build your signal engineering setup
If this post made you think about your own paid marketing feedback loops, join the workshop and map the signal architecture for your setup.
Join the workshopJoin the newsletter
Get bi-weekly insights on analytics, event data, and metric frameworks.