The Wave — notes on a shifting analytics landscape

In January I decided I won’t build a commercial product.
Building is not the problem anymore. With what’s available now you can spin up something functional over a weekend. I did it four times in the last few months. Four tools I actually use regularly, built in sessions I wouldn’t even call serious. The coding part, which was always my bottleneck, not my natural habitat, is no longer the bottleneck.
So the blocker I always had is gone. And still I decided not to go ahead.
The real problem is distribution. Getting people to find it, trust it, pay for it, keep paying for it. That hasn’t changed. It’s still brutal, it still takes years, and it’s still not fun — especially when consulting pays well and gives you faster, cleaner feedback. When you stack the two paths next to each other honestly, the product path becomes much harder.
But that’s not the whole story. Underneath the distribution reason there was something else sitting. A question I kept coming back to: even if I built it and distributed it, does it have a place in the world that will still exist in two years?
That question is what this post is about.
The Pattern
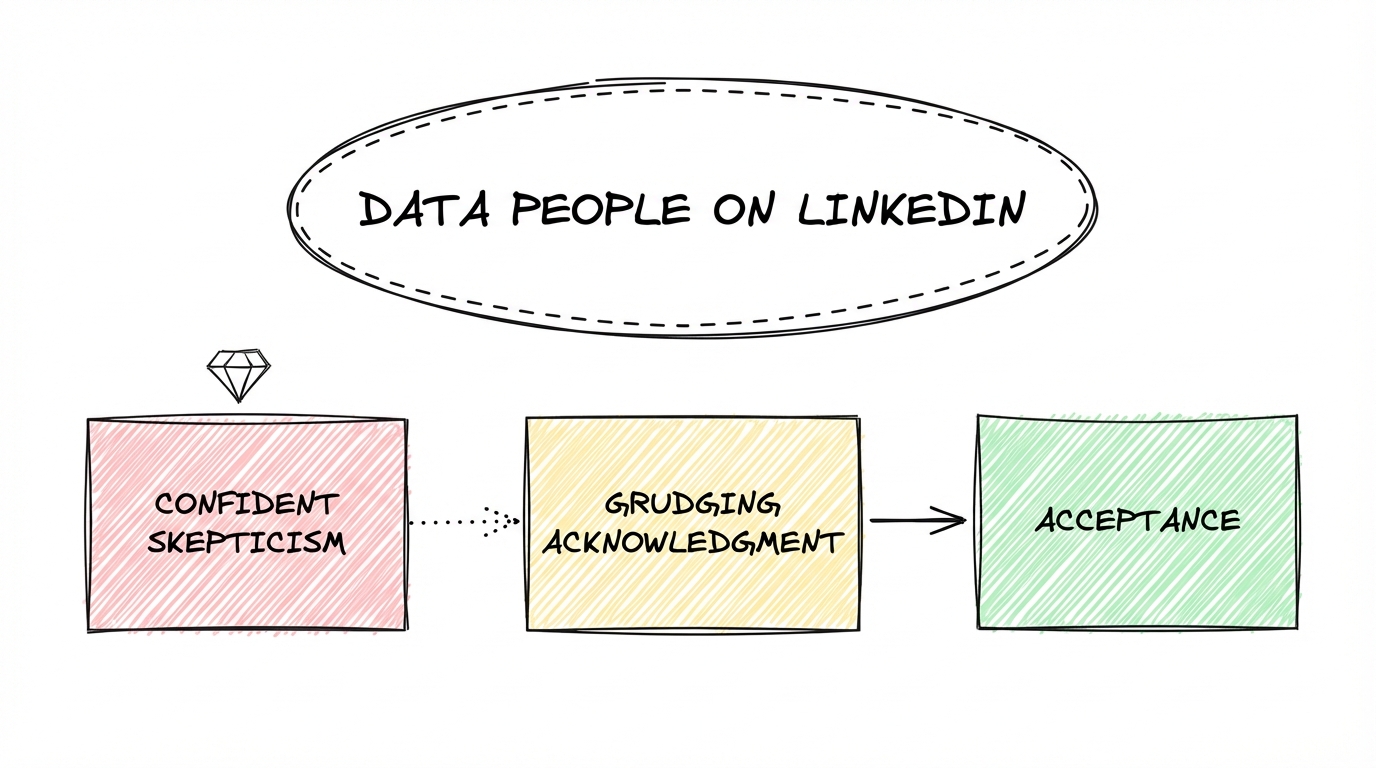
If you follow data people on LinkedIn you’ve watched something play out over the last six to twelve months. The arc is pretty consistent.
First came the confident skepticism. “Sure, AI does interesting things, but I don’t really see it in data engineering yet.” Said with authority, sometimes with a little smugness. The reasoning was fair enough — try a one-shot prompt, hit the limitations fast, conclude the technology isn’t there.
Then came the grudging acknowledgment. The results got harder to dismiss. People started posting Claude Code outputs that were genuinely impressive. The tone shifted from skepticism to qualification. “Yes it can write the SQL, but can it design a semantic layer?” “Yes it builds the pipeline, but what about edge cases?” “Yes it works for simple setups, but real production environments are different.”
The “but” is always real. The limitations exist. Nobody is claiming otherwise. AI-bros excluded from that.
The problem is that the “but” keeps moving. What required heavy context engineering six months ago works reasonably out of the box now. What works out of the box now will probably require almost nothing in another six months. Take the delta between where things were and where they are, apply a conservative discount, project forward. The curve is still steep.
Most people engaging with this are testing the waters. One-shot prompts, quick experiments, surface-level conclusions. The people who go deeper — who actually invest in context, who push the tools past the obvious use cases — are finding the limitations and potentials further out than the skeptics suggest.
The wave isn’t theoretical anymore. The question is just how fast it’s moving and what it hits first.
Walking the Stack
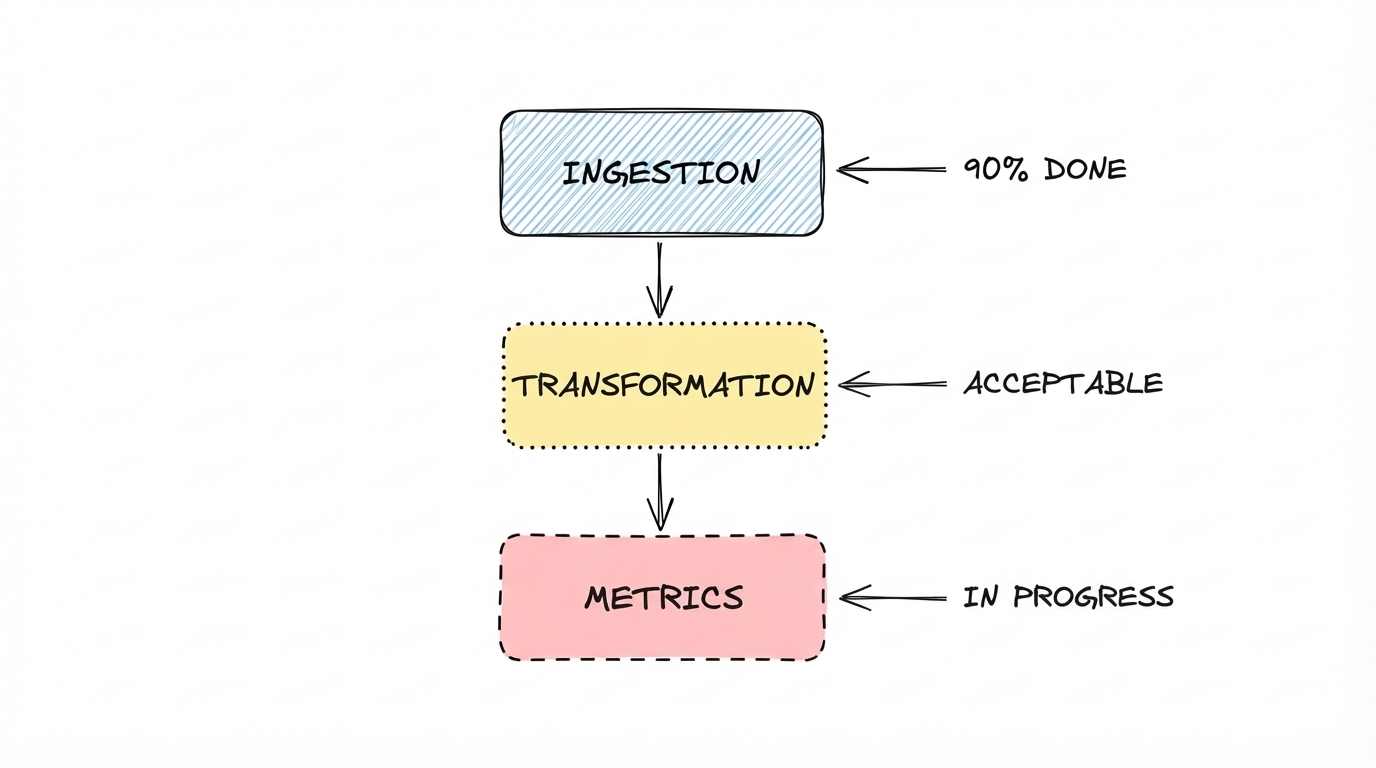
Let me go through the data stack layer by layer. Not to be dramatic about it, but to be honest about where things actually stand.
Ingestion
For the 90% case, this is largely done.
Give Claude Code a reasonably documented API, a principle file with some basic opinions, point it at DLT for the pipeline scaffolding and Dagster for orchestration, and you get something production-ready in a session4. I have a setup running on a cheap VPS right now that took about an hour end to end. Is it the most bulletproof thing in the world? No. But it runs, it handles schema changes, and it does what it needs to do.
The 10% case — the nightmare APIs, the high-volume edge cases, the stuff that gives engineers bad dreams — is real. People write a lot of blog posts about it. It’s also mostly not what most teams deal with most of the time. For the actual work, the common work, the wave has already arrived.
Transformation
This one requires some honesty about the bar.
Claude Code will build you a dbt setup that looks like a lot dbt setups in the wild. Which is to say: not elegant, not deeply considered, functional enough. If you’ve spent time in the intermediate layers of real production data models you know what lives there. Scary things. Half-finished logic, redundant CTEs, naming that made sense to one person once.
Claude Code produces roughly the same. The difference is it produces it in minutes.
Add some context: opinions about data modeling, a skill file with your preferred patterns — and it gets noticeably better. I have a handful of these now and the output quality jumps. The argument that transformation requires deep human expertise to get right is true. It’s also true that most transformation layers in production weren’t built with deep human expertise. The bar Claude Code has to clear is not the theoretical ideal. It’s the actual average.
Semantic layer and metrics
This is where people feel safest. And they’re not entirely wrong, but the reason they’re right is not the one they usually give.
The semantic layer is still hard. Metrics are still contested and messy. Business definitions still vary by team, by context, by who you ask on which day. AI doesn’t solve this.
But here’s the thing. Humans haven’t solved this either. Every data team I’ve worked with has struggled with metric alignment. Not because of tooling, not because of technical complexity — because getting different business teams to agree on a shared definition of revenue, or activation, or churn, requires ongoing organizational work that most companies don’t do well. It requires someone with enough authority and persistence to drive it through.
That failure predates AI. AI doesn’t fix it. But it also doesn’t make it worse. The semantic layer is unsolved for the same reason it’s always been unsolved. Which means it’s not really high ground — it’s just a different kind of stuck.
The missing piece
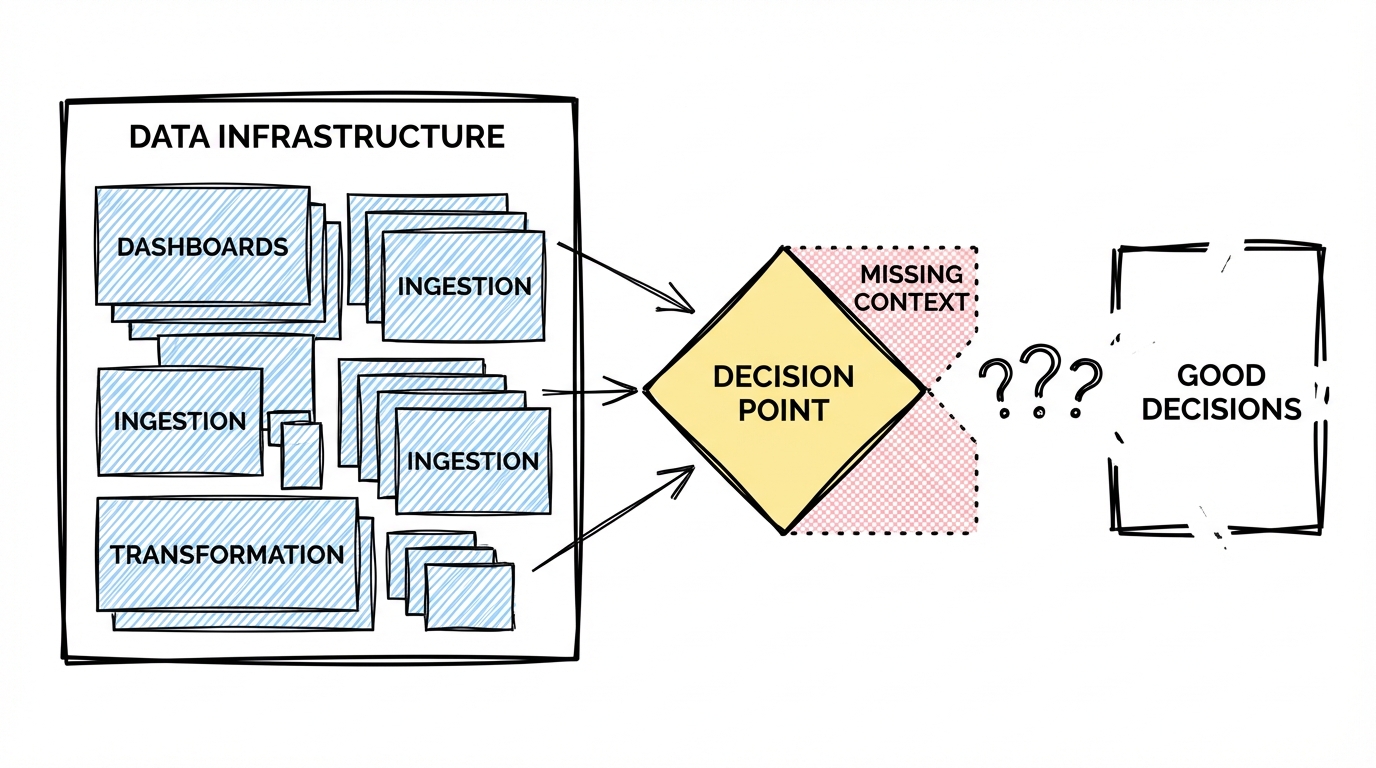
The whole point of a data setup, underneath all the ingestion, transformation, and dashboards, is decision preparation and sometimes execution. Giving people solid context to make a call about a business process, an investment, a strategic direction.
That’s the job. Everything else is infrastructure for it.
And right now, that job is where AI genuinely struggles. Not because the models aren’t capable enough. Because the context isn’t there.
To prepare a good decision you don’t just need the data. You need to know what the decision actually is. You need to understand the business strategy behind it. You need to know which teams are involved, how they work, what they’re optimizing for, where the politics sit. You need the full picture, not just the numbers, but the organizational layer that gives the numbers meaning.
A really good data person does exactly this. They don’t just pull metrics. They go deep into how the business operates, climb up to the strategy layer, and hold both at the same time. That’s what makes the difference between an analysis that gets used and one that gets filed away.
Right now if you open Claude and throw a business problem at it, you get something useful but incomplete. The model is working without the organizational context that a good analyst carries in their head. You can feel the gap.
But I don’t think this gap stays open much longer.
The threshold that changes everything is organizational memory1. Right now Claude sessions are personal and isolated. Your context is yours. What’s completely missing is a shared company memory — the accumulated knowledge of how an organization thinks, decides, and operates. There are tools trying to bridge this. They work as an intermediate. I’m not sure how long they stay relevant as an intermediate.
Once the memory problem is solved at the organizational level, the next piece is the loop. The ability to refine, evaluate, and improve outputs over time without constant human steering. This is already working impressively at the personal level2 3. The extrapolation to the organizational level is not a huge leap — it’s more an engineering and architecture problem than a conceptual one.
Put organizational memory and loops together, apply them to a company’s data and strategic context, and decision preparation stops being a human-led process with data as an input. It becomes something closer to decision assistance. And from there, in some domains, decision making.
We are not there. But we are also not far.
The Middle Collapses
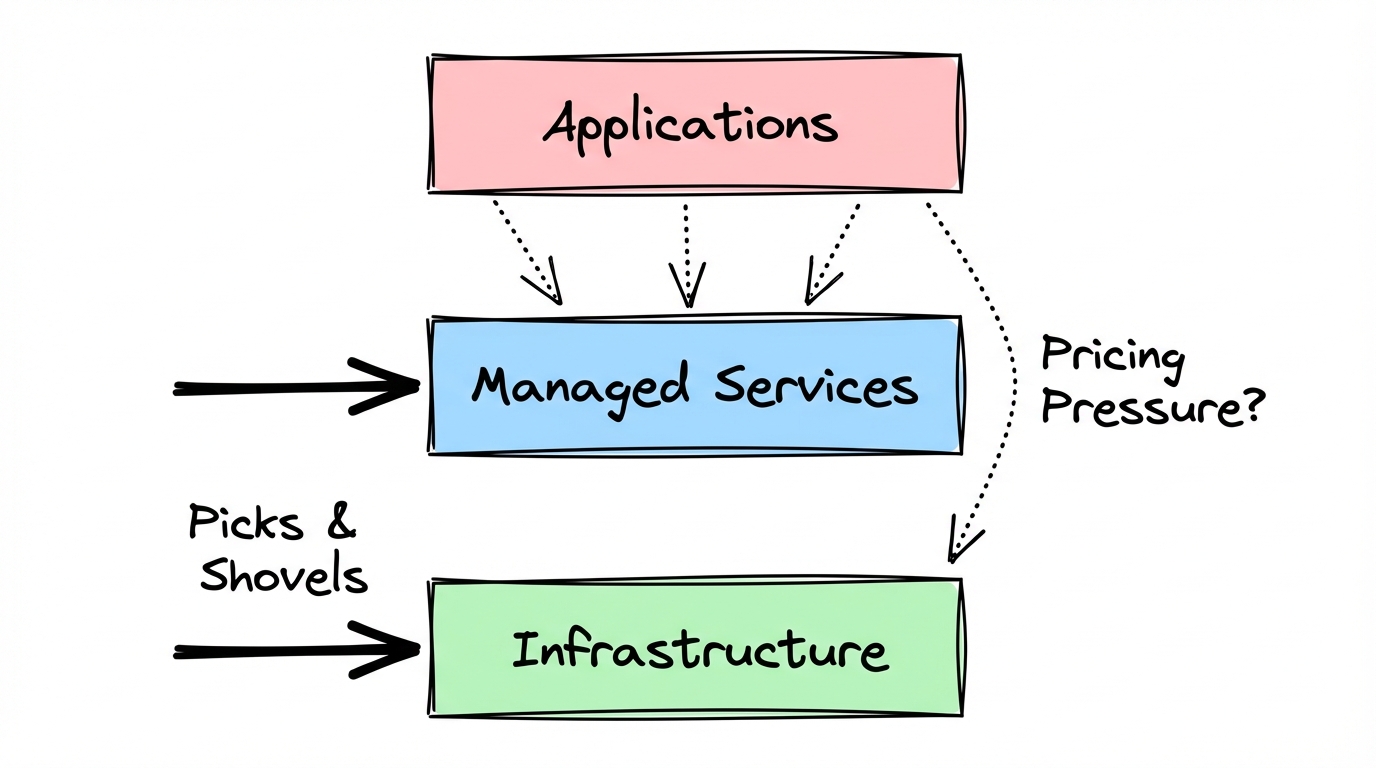
So where does this leave the tools?
Infrastructure will stick around. The picks-and-shovels layer: compute, storage, the pipes that move data at scale. That has a clear value proposition that doesn’t depend on what sits on top of it. Managed services will stick around too. Having someone else take responsibility for running and maintaining a system still has real value, and that value doesn’t disappear just because building the system got cheaper. But it might increase the pricing pressure.
The danger zone is the middle.
Most data tooling lives in the middle. Tools that do one or two jobs well enough. A pipeline tool. A transformation layer. A dashboard product. A product analytics platform. Each one solving a specific problem, each one charging for that solution. Sounds like modern data stack spirit.
That value equation is getting squeezed from both ends simultaneously.
From below: anyone with an engineering mindset can now build a functional version of most of these tools for their own use case over a weekend. Not for Amazon scale. Not for every edge case. But for the actual problem they have, in their actual organization, without paying for a seat or negotiating a contract or waiting for a feature request.
From above: the AI platform layer is eating features steadily. Not all features, not immediately, but consistently. And the pace is not slowing down.
The tools caught in the middle have to answer a question that’s getting harder to answer convincingly: what do you offer that justifies the distribution tax? The sales cycle, the onboarding, the ongoing cost, the organizational buy-in required to adopt and maintain a vendor relationship. That tax was always real. It was worth paying when the alternative was months of engineering work. When the alternative is a weekend session and/or a principle file, the math changes.
I’m not saying every tool in the middle dies tomorrow. Distribution is still hard, switching costs are real, and organizations move slowly. There’s runway. But the direction is clear enough.
The Honest Ending
New things will emerge. They always do.
The history of technology is not a history of categories dying and leaving nothing behind. It’s a history of categories transforming, compressing, and spawning things that weren’t predictable from the previous vantage point. The wave doesn’t leave an empty beach.
But I can’t tell you what the new things are. And I’m suspicious of anyone who can.
Right now there’s too much in motion. The organizational memory problem isn’t solved yet. The loops are early. The platform capabilities are improving faster than most people’s mental models of them. Making confident predictions about what data work looks like in three years feels like reading a map of a coastline that’s actively changing shape.
What I can say is this. If you are a data practitioner, the question worth sitting with is not “will AI replace me.” That’s the wrong frame. The better question is: how much of what I do right now lives in the middle? How much of my value is tied to work that exists because building and maintaining things was hard? And how much of it is tied to the organizational layer: the strategy, the context, the human judgment about what decisions actually matter?
The first kind of value is getting compressed. The second kind is harder to compress. The gap between them is where the wave hits hardest.
I decided not to build a product because I could see the wave clearly enough. Not all of it. Not where it ends up. But clearly enough to focus on other things (my good old friend/foe consulting).
That’s probably enough to work with.
1 For an interesting deep dive into how memory systems for AI agents work, see I Studied OpenClaw Memory System.
2 Ralph — an autonomous agent that runs eval-driven improvement loops.
3 Gastown — Steve Yegge's experiment with self-improving AI agents.
4 Building a production data pipeline with Claude Code — a walkthrough showing how well this works in practice.
Join the newsletter
Get bi-weekly insights on analytics, event data, and metric frameworks.